1.弱监督
1.1弱监督分类
不完全监督
标签只标注一部分
不确切监督
粗标注,或者跨label的标注
不精确监督
标签中有错误标签
只针对上述的两种做简单介绍
1.2不完全监督
使用少量的标签进行监督训练。局限于单模态的监督训练
3D点云语义分割
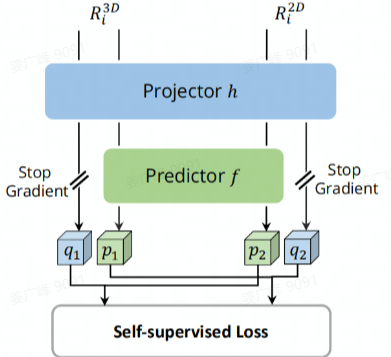
1.Image Understands Point Cloud: Weakly Supervised 3D Semantic Segmentation via Association Learning
To avoid extensive annotation, we assume very few labels of
point clouds are given (e.g., 1% or fewer), and each
category has at least one labeled point. 2D images
3D Box
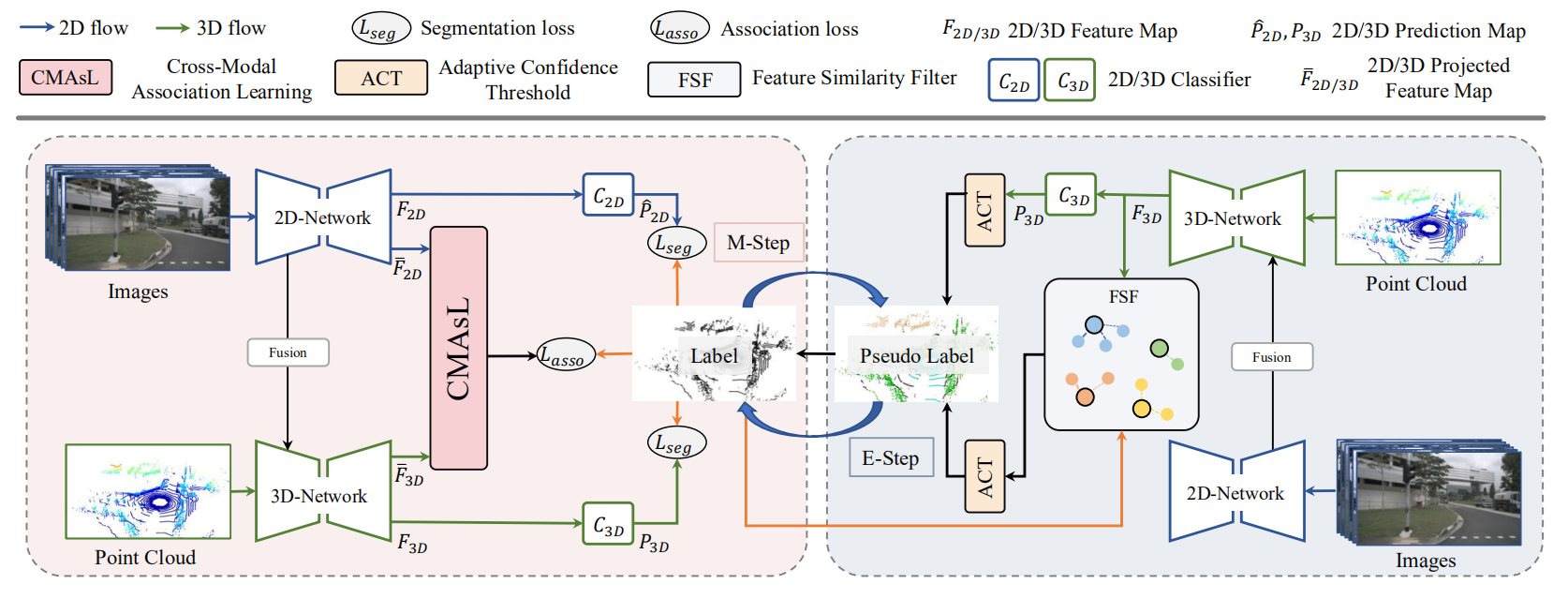
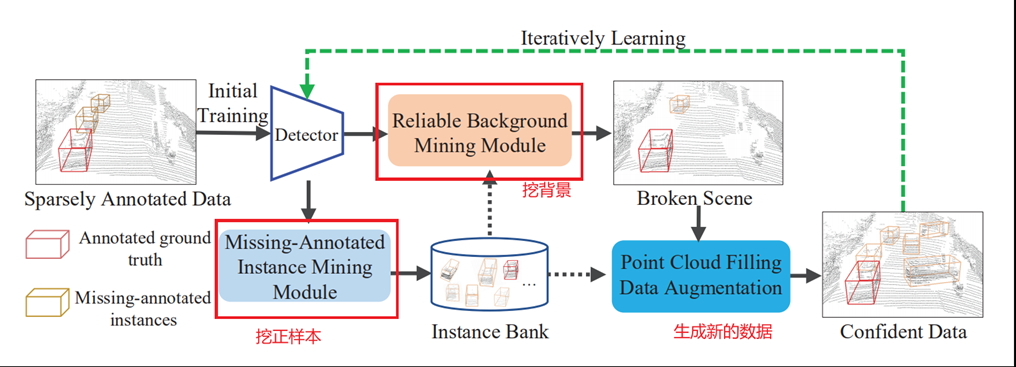
2.SS3D: Sparsely-Supervised 3D Object Detection from Point Cloud
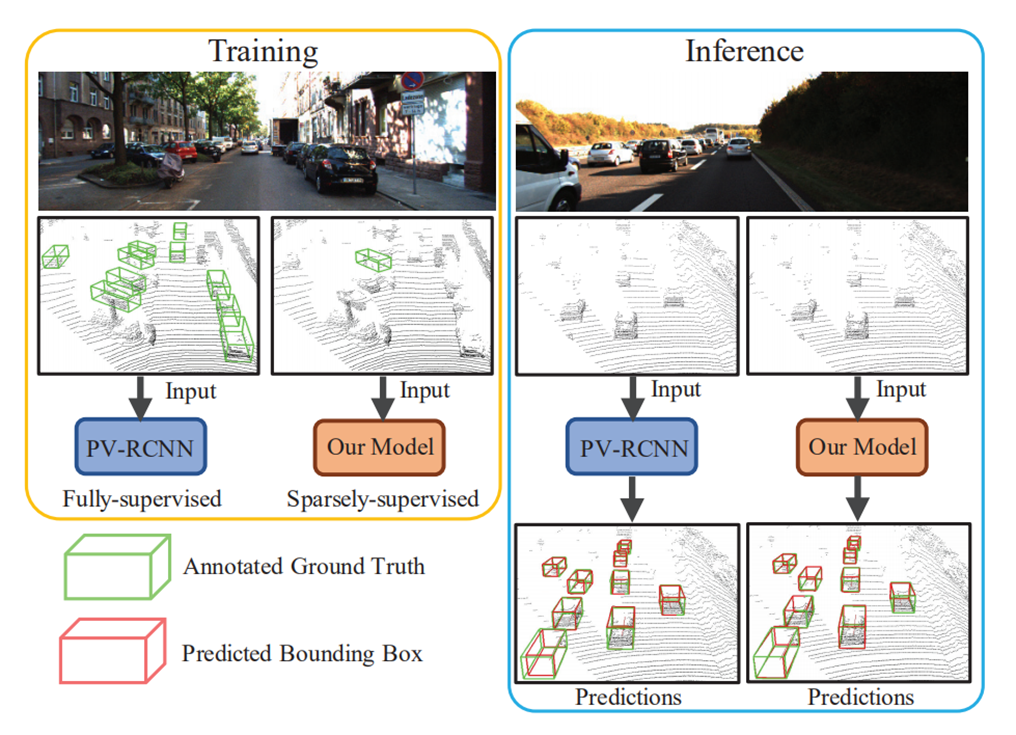
主要实现办法是用高置信度迭代挖掘正实例和背景,进一步使用生成的这些数据来训练3D detector。
1.3不确切监督
单模态
Scene-level监督3D Box
1.3D Spatial Recognition without Spatially Labeled 3D
仅使用scene-level tag进行监督。什么是scene-level的tag?仅表示这个场景下是否存在该类别,不知道在哪、有几个等其他额外信息。
Box监督mask(语义信息)
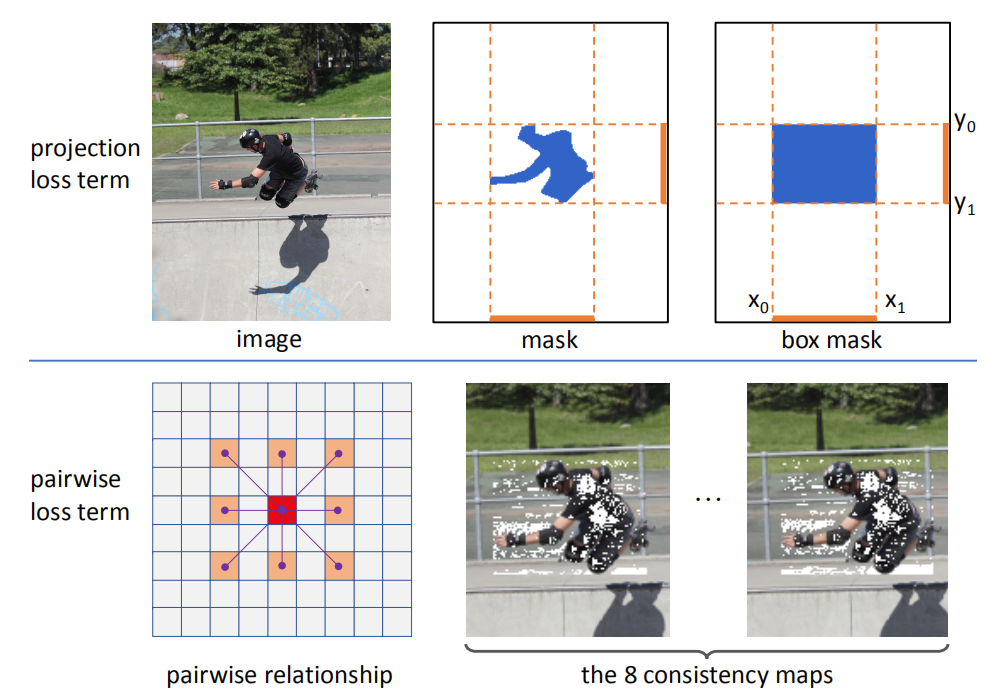
2.BoxInst: High-Performance Instance Segmentation with Box Annotations
由GT Box来监督生成图片的mask。
作者设计两个loss来监督mask的生成,其中有启发的是使用了相邻像素的颜色相似度。
多模态交互
2D的标签(mask、gt)来监督3D的task
3.FGR: Frustum-Aware Geometric Reasoning for Weakly Supervised 3D Vehicle Detection 2021
4.MAP-Gen: An Automated 3D-Box Annotation Flow with Multimodal Attention Point Generator 2022
2.自监督
自动为数据产生标签
Pre-training来挖掘数据的关系,然后再用于训练网络进行目标检测等。
多视图的数据增强,然后捕获其中的不变性(BOX的几何不变性)一致性损失函数设计。可能基于点,基于proposal,基于voxel等等。
1.ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
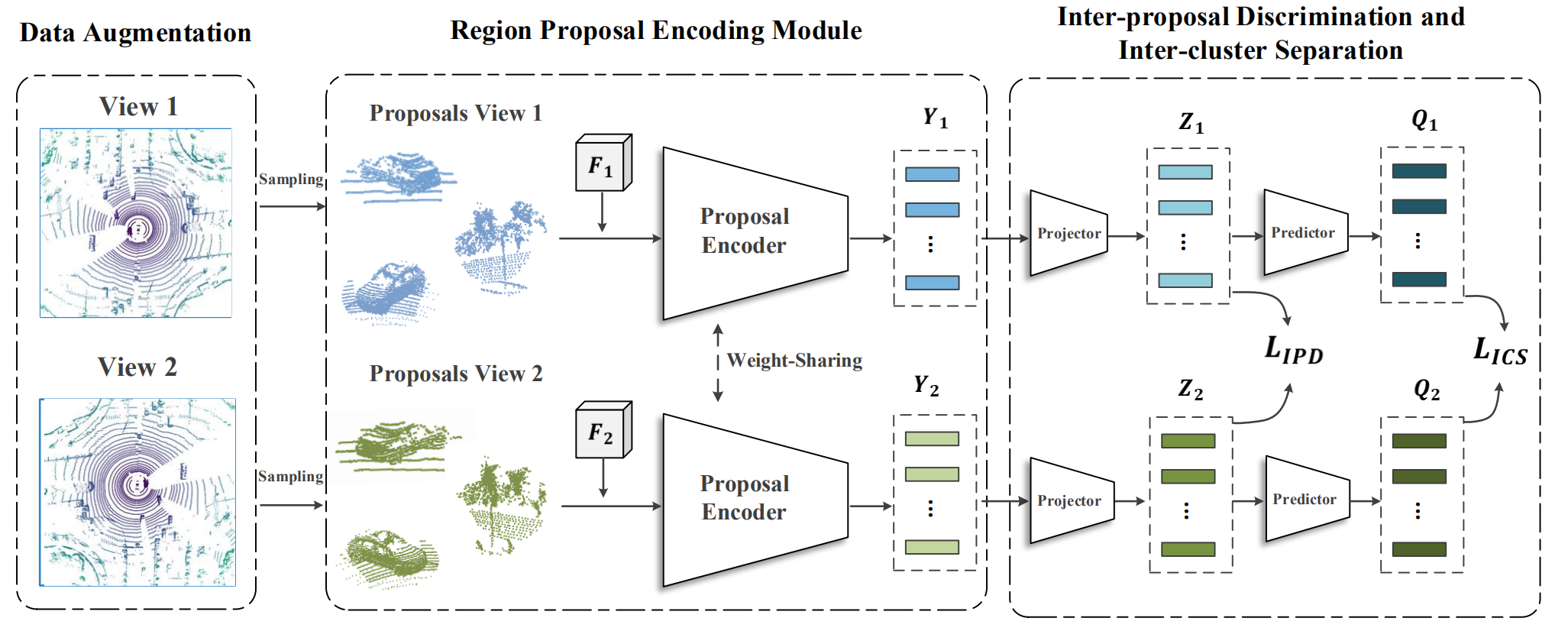
- 自监督训练——mask掉一部分点然后去训练网络学习内部关系 voxel-mae、mae。
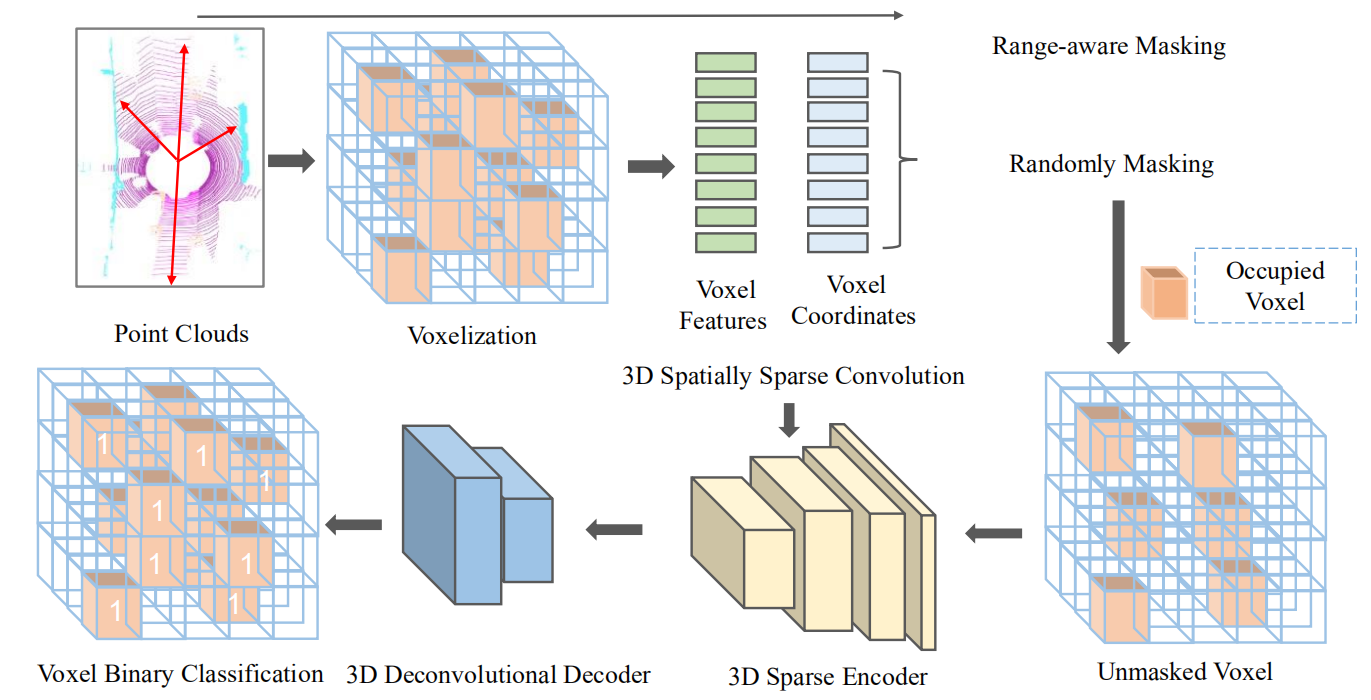
2.Voxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds
用Unmasked Voxel来输入Encoder,然后非对称的Decoder来预测Voxel是否被占用(二分类问题),Masked和Unmasked的GT都是1,使用交叉熵来计算 loss。
- 多模态的自监督—2d box和3d box之间。