Instance segmentation is a fundamental research in computer vision, especially in autonomous driving.
However, manual mask annotation for instance segmentation is quite time-consuming and costly.
To address this problem, some prior works attempt to apply weakly supervised manner by exploring 2D or 3D boxes.
However, no one has ever successfully segmented 2D and 3D instances simultaneously by only using 2D box annotations,
which could further reduce the annotation cost by an order of magnitude.
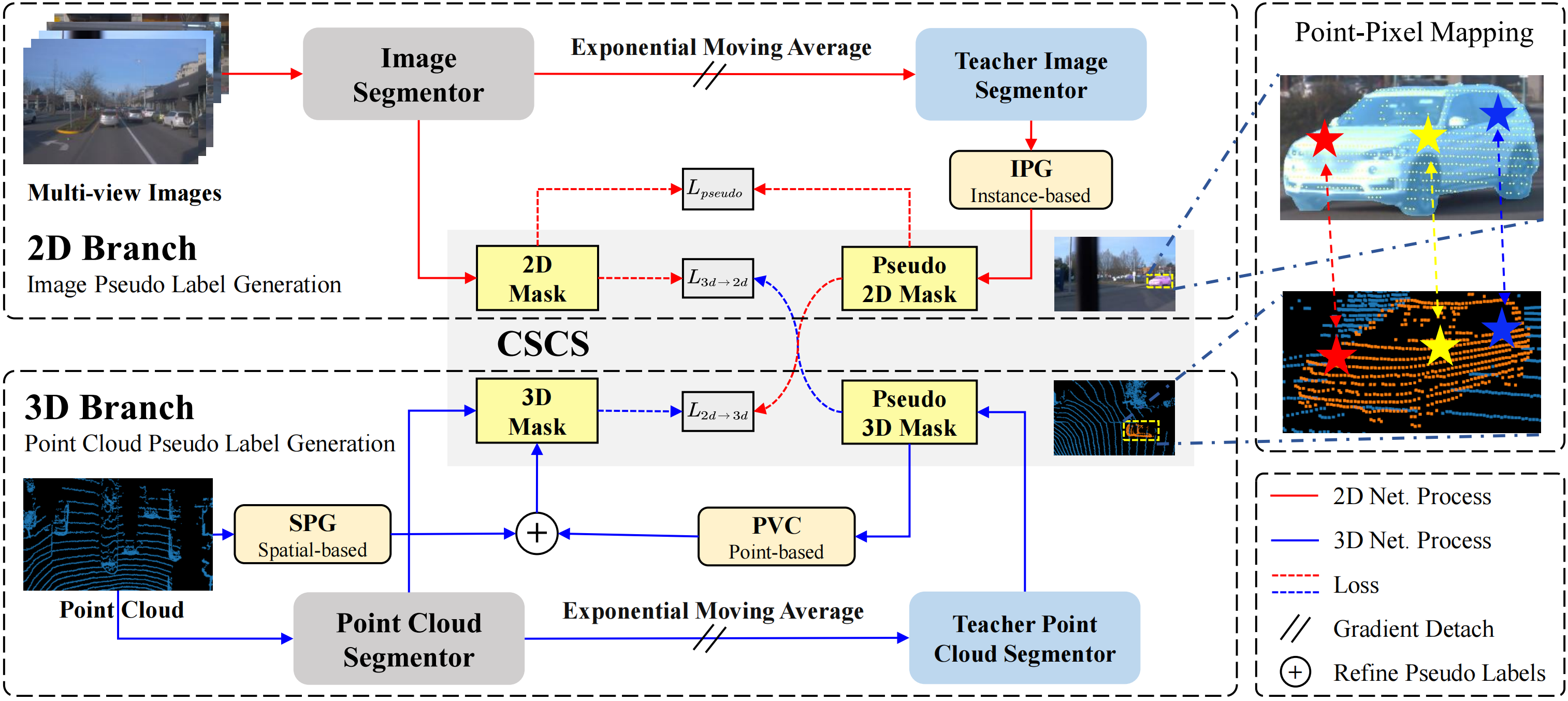
Thus, we propose a novel framework called Multimodal Weakly Supervised Instance Segmentation (MWSIS),
which incorporates various fine-grained label correction modules for both 2D and 3D modalities, along
with a new multimodal cross-supervision approach. In the 2D pseudo label generation branch, the
Instance-based Pseudo Mask Generation (IPG) module utilizes predictions for self-supervised correction.
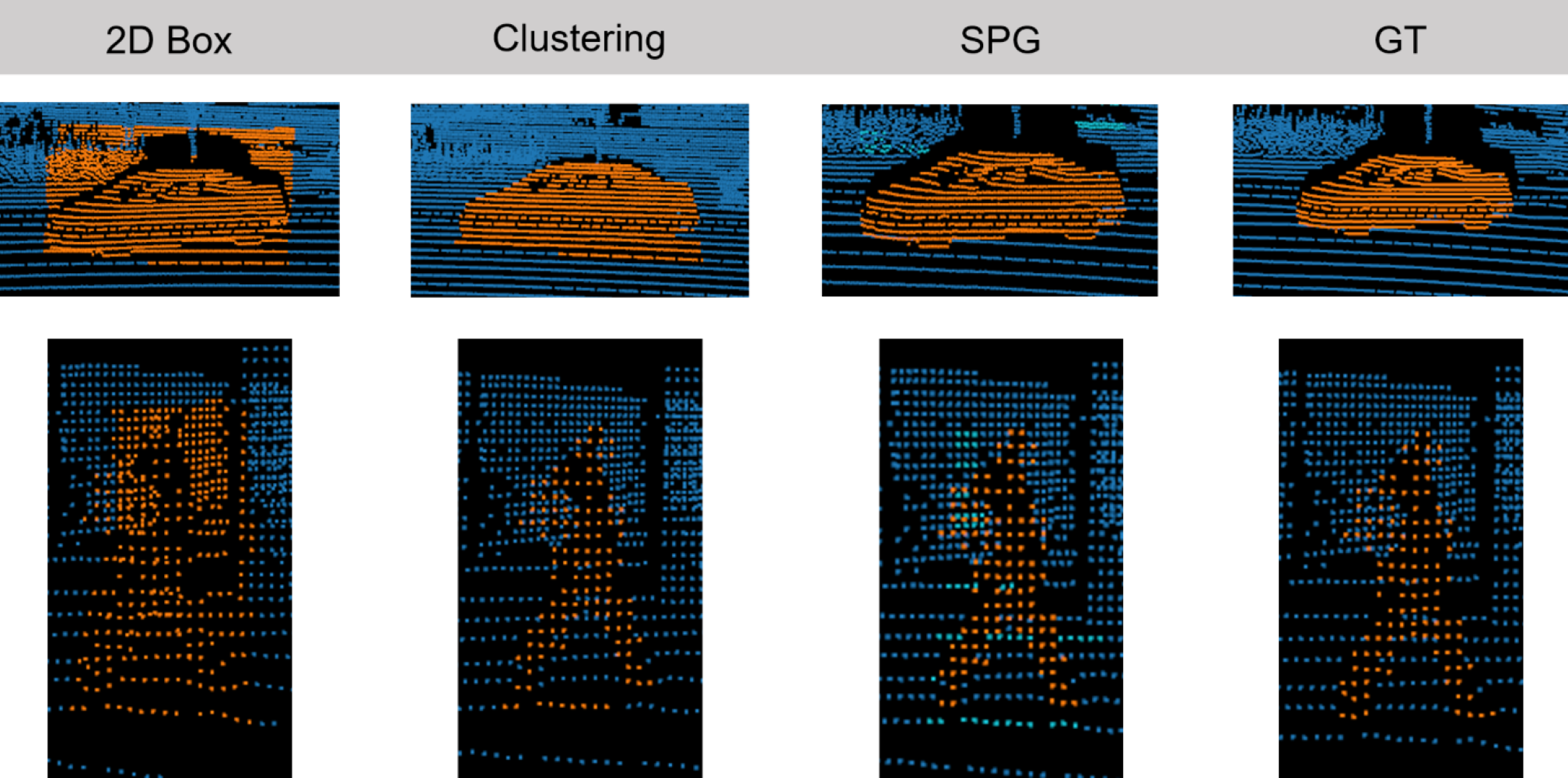
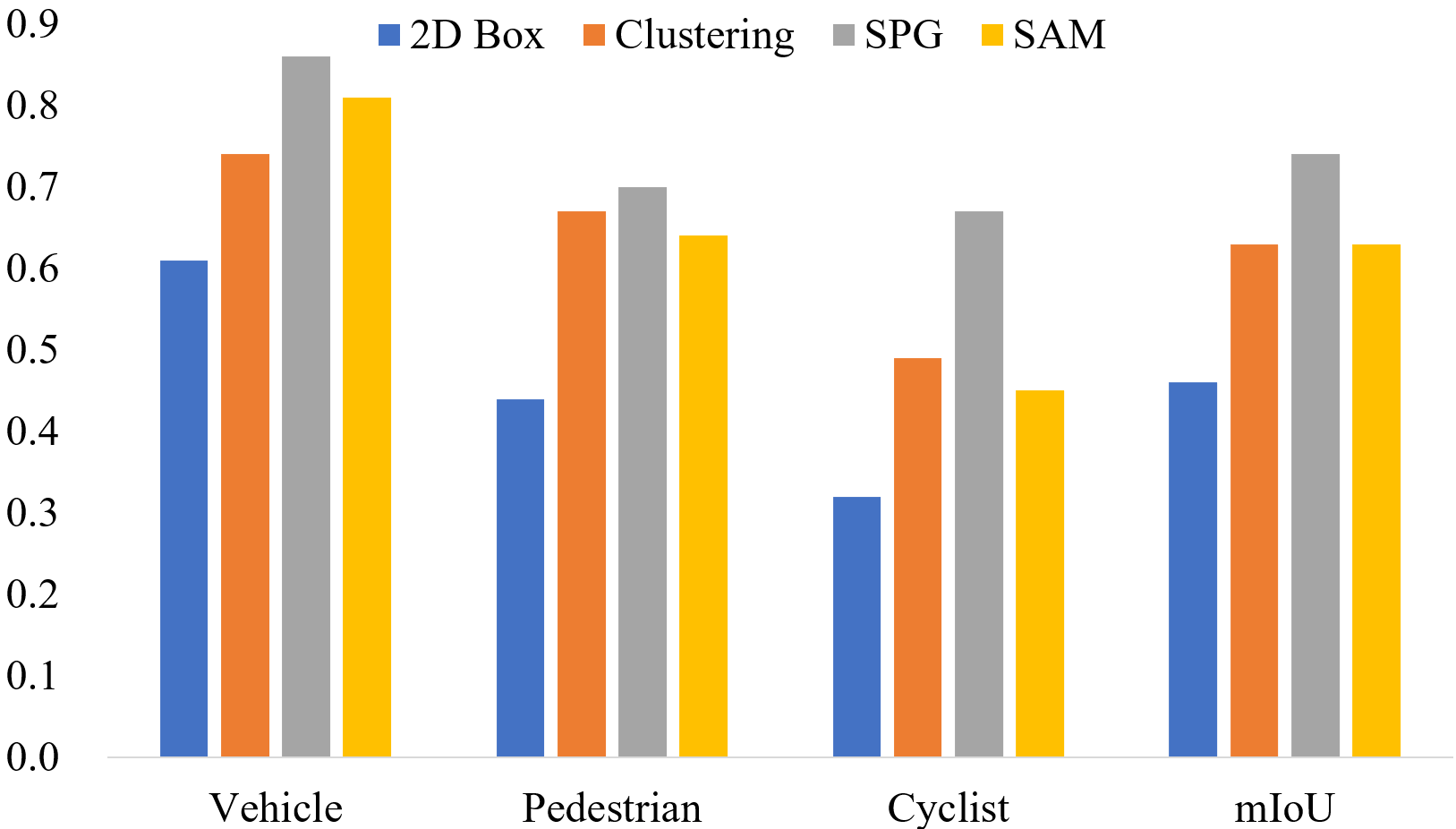
Similarly, in the 3D pseudo label generation branch, the Spatial-based Pseudo Label Generation (SPG)
module generates pseudo labels by incorporating the spatial prior information of the point cloud.
To further refine the generated pseudo labels, the Point-based Voting Label Correction (PVC) module
utilizes historical predictions for correction. Additionally, a Ring Segment-based Label Correction (RSC)
module is proposed to refine the predictions by leveraging the depth prior information from the point cloud.
Finally, the Consistency Sparse Cross-modal Supervision (CSCS) module reduces the inconsistency of
multimodal predictions by response distillation.
Particularly, transferring the 3D backbone to downstream tasks not only improves the performance
of the 3D detectors, but also outperforms fully supervised instance segmentation with only 5%
fully supervised annotations.
On the Waymo dataset, the proposed framework demonstrates significant
improvements over the baseline, especially achieving 2.59% mAP and 12.75% mAP increases for 2D and
3D instance segmentation tasks, respectively.